


Sistema reconocimiento y extracción de información vía OCR
Desde hace algunos meses, nuestra empresa se encuentra desarrollando junto Sinapsis (especialistas en el desarrollo de soluciones para el sector financiero) un sistema de procesamiento de documentos escaneados para poder catalogar y extraer información de los mismos mediante OCR.
¿Qué es el sistema OCR?
Un OCR (Optical Character Recognition) es un sistema computarizado de análisis que permite escanear un documento de texto en un fichero automatizado electrónicamente, que se puede editar con un procesador de textos en el ordenador.
El Reconocimiento Óptico de Caracteres (OCR) es el reconocimiento de la máquina de caracteres de texto impreso.
Los sistemas de reconocimiento óptico de caracteres (OCR) son capaces de reconocer numerosos tipos de fuentes de texto y caracteres de imprenta de máquinas de escribir y computadoras.
¿Cómo lo hacemos?
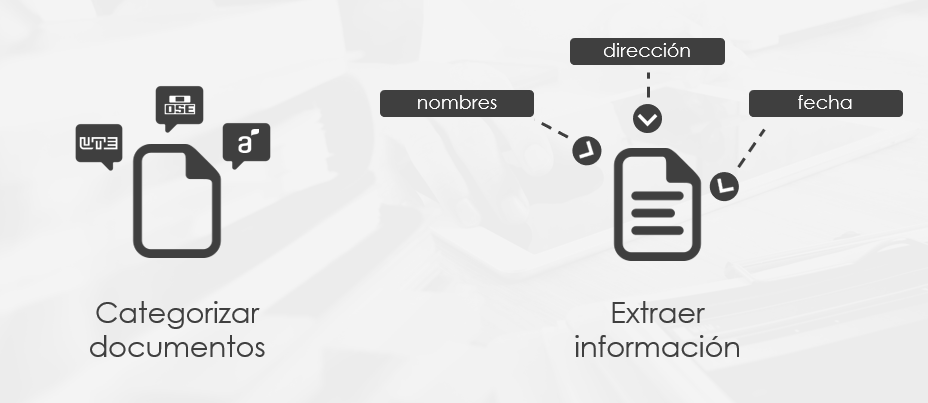
El sistema permite definir reglas de identificación de documentos, por ejemplo para determinar si lo que se está procesando es una factura de Antel, OSE (Imagen 1) o un documento de identidad, y reglas de extracción de datos para cada tipo de documento. Por ejemplo de una factura extraer fecha de vencimiento y dirección de facturación, asi como de un documento de identidad extraer su número y fecha de expiración.

La ventaja de esta definición de reglas es la posibilidad de configurar nuevos tipos de documentos y datos a extraer (Imagen 2) de forma dinámica a medida de cada cliente, así como también poder incorporar nuevos tipos de documentos sobre la marcha de forma rápida y sencilla.
Con este automatismo se mejora enormemente la productividad al no tener que transcribir la información de los diferentes documentos. Se digitaliza la información lo cual permite hacerla disponible para todos, realizar búsquedas e integrarla a diferentes sistemas.
"Fx2 ha respondido perfectamente, el proyecto salió en el tiempo definido, la comunicación fue casi diario. Estamos muy contentos con el resultado"
AQVA
Luis Machado, responsable de TI de AQVA